PART I of IV: How Far Have We Come and Where Do We Stand
This is the first of four blogs on predictive coding that
I will be posting in the next month.
This first entry will focus on how the technology and use of predictive
coding has changed and where exactly it stands in the industry today. The second will analyze and discuss the
impact predictive coding has had on reviews and review attorneys compared to predictions
regarding the same. The Third will cover
case law on the topic. Finally, the fourth will provide some predictions about
what the future holds for predictive coding (yes, more predictions).
I am writing these blog entries in part due to my
participation in the upcoming ACEDS conference, where I will be speaking on a
panel about Information Governance. This
four part blog series will appear in the conference material as a part of that
panel. If you are interested in the
field of eDiscovery and pragmatic discussions about eDiscovery issues framed in
the context of real life situations involving real people, I suggest you consider
attending the conference, which will be held in Hollywood Beach, Florida, April
27-29. Additionally, I believe the ACEDS
eDiscovery certification is a worthwhile endeavor and certification. If you would like more information about it,
it can be found on the ACEDS website (www.aceds.org), or feel free to contact me as well.
Now, enough with the longwinded introduction and onto the actual
substance of the entry:
For the past several years, predictive coding has been
the topic de jour in the eDiscovery industry.
It was discussed at every conference and software vendors were
scrambling to add a predictive coding module or functionality to their tool and
clamoring to show its ROI and impact, often unrealistically overstating reality. The former is no longer the case, as the
industry has moved on to Bring Your Own Device (“BYOD”) as the current hot
topic. However, this is not because predictive
coding was a fad or no longer matters, rather it is because it has maturated as
a concept within the industry; when you mention predictive coding now in the
legal industry, there is a general understanding of the concept and paradigm,
and you will receive nods of general awareness rather than blank stares from
those you are talking to. Within the
group of those intimately familiar with predictive coding, the distrust of the
technology has subsided, and the distrust is often now focused on the process
employed to run it and whether there has been sufficient training rather than
the concept or idea itself.
The term Predictive coding AKA Technology assisted review
(“TAR”) or Computer Assisted Review (“CAR”) among others, has itself grown and
expanded, and although people have different thoughts of which is the most
accurate term to use, in a very broad sense it is understood within the
industry to refer to a technology and process whereby advanced mathematics is
leveraged in combination with human input (generally coding) to cull or group a
population of documents. The exact
workflow and technology differs by platform and matter, but generally the idea
is to leverage technology to reduce the amount of material that is reviewed by humans
in an accurate and defensible manner.
The concept itself has gained enough traction that EDRM developed a
framework for it known as the Computer Assisted Review Reference Model (“CARRM”):
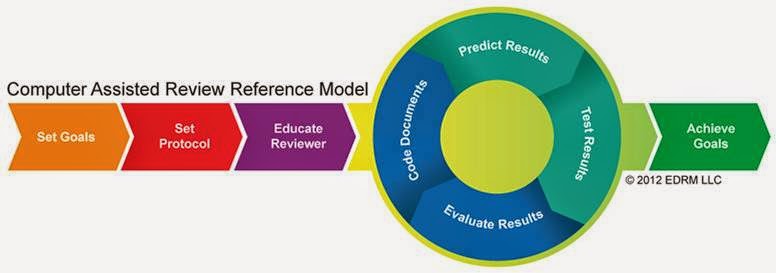
Despite the growing knowledge base and understanding of
the concept, (as opposed to just the knowledge of the term), that has not
necessarily translated into vastly increased use of the technology. I was at a recent industry event where the
presenter engaged in a bit of ad hoc polling.
One question they asked was how many people knew what predictive coding
is. The response was universally yes,
the participants did know what predictive coding is. He then asked how many had actually used
predictive coding on a live project.
About 60% of the audience indicated they had. However, when asked how many times they had
used the technology, for most, the answer was only once or at most twice. This can be attributed to many things including
the fact that the industry has only started to accept predictive coding
technology relatively recently and hence there have not been many opportunities
for many companies to use the technology multiple times. But while lack of opportunity speaks to this
number in part, there is more to the story.
Most people who I have spoken to not only used predictive coding
technology relativity few times, but they have done so despite having multiple
opportunities to use it, but for which they chose not to. I would say many companies will use the
technology in one in ten or one in fifteen cases, by choice after considering
the predictive coding option.
So why are companies choosing not to use predictive
coding in every matter or project? There
are a number of reasons, a few of which include:
- The Cost of the Technology – predictive coding
is often an extra or add on expense to purchase that is not included as a part
of standard technology licensing or even for use on an ad hoc basis. Even if a company or attorney would like to
use the technology, there simply may not be budget to purchase the technology. If the cost comes down, not surprising it
will be used more often.
- The Technology is not
Viewed as Being Effective Enough– not all predictive coding tools are created
equal, even if the core technology they rely on is very similar or even the
same at times. Whether it is the base
technology, the user interface, or the transparency and reporting of a particular
tool, perceived deficiencies regarding some or all of these aspects can turn a
user off of a particular tool. If the
tool a company spent large amounts to license and work into their processes has
sub-par predictive coding functionality, they are not likely to abandon the
tool just to utilize predictive coding, at least not quickly. I work with one client who has an ECA tool
and they were given the predictive coding module for that tool as a part of
their license. Nevertheless, after testing
they are hesitant to use the module on live data because it lacks transparency and therefore
trustworthiness regarding how it makes its decisions and the developers/sales
people are unable or willing to explain and clarify better. This is not a judgment or decision on
predictive coding as a whole, but rather on the particular tool available to
this client. For them it poses too great of a risk to use outside of
testing.
- The Human Cost to Use
the Tool is Too High For the Matter – even if you can afford to purchase or license
the of your choice technology, it takes human time and expertise to use and
train the predictive coding technology.
Often the person training the system is one who is the most
knowledgeable about a matter. At the
beginning of the matter this is often a partner or high-level associate, both
of whom bill at a higher rate than a junior associate and certainly more than a
review attorney. While the technology generally
works the same on small and big cases, due to the mathematics of sampling,
there is a minimum amount of training and sampling that must normally be done
in a predictive coding project regardless of population size. If the document count falls below a certain threshold,
normally 50,000 documents give or take, it can often cost more for the higher
priced lawyers to complete that training than will be gained by reducing the
review population via the technology. Additional
related considerations is finding the time and pressure to make that partner or
high-level associate actually review and train the system on several thousand
documents, which can take days. This is
not an activity they typically perform and it can be like pulling teeth to get
them to do so. Thus, actually
implementing a predictive coding project can be difficult to coordinate and
implement.
- The Matter or
Material is Too Sensitive – there are simply some matters that are so
important to a client, perhaps because the matter at issue threatens the very
core and existence of their business, or the money and negative PR at issue is
just so great, that they want eyes on review of every document. While you could still use predictive coding
technology to group and organize such a review, given that all documents will
be looked at, decision makers often feel the time and expense of predictive
coding is simply not worth it in such a case.
- The Party Receiving the
Data Does Not Agree – this is most applicable when the government is requesting
something. If the DOJ “suggests” you not
use predictive coding, most people listen.
That is not to say that the DOJ is necessarily opposed to using
predictive coding, in fact they have agreed to its use previously, including
the high profile Anheuser-Busch InBev/Modelo merger (more on that in part three
of this series), but they do not always agree to its use as a matter of course,
which will obviously impact the responding party
What my experience has taught me is that at the end of
the day, the clients and companies footing the bill like predictive coding because
it saves costs. Most are hands off in
the process and details and are only generally aware that it is going on or
being used. While they want to comply
with their duties to produce, it is the cost savings, not the arguably more
accurate and consistent results that drives their adoption of the technology. If the cost savings are not there they are
not using it, and often that decision is being made on a matter by matter basis. Even when the cost savings are there, that
provides the motivation to push counsel to agree to its use, which is not
always easy either. Just as there are
attorneys who still prefer to review paper, there are many more that are
unwilling to avoid review of documents that hit on a search term just because a
computer indicated they possibly could.
So on any given project, there are multiple hurdles to pass before
utilizing predictive coding, even when the technology itself works well or even
when the economics of it make sense.
What does all this mean?
Well, I suggest that it means the concept and idea is stable and
accepted (even if understood on a superficial level by many, it is nevertheless
understood now), and it will continue to be used and in fact its use should
increase. Similarly, software developers
will continue to develop the technology because their customers will demand
they do so. However, and despite that, predictive
coding will not be used in all matters, and may not even be used in most
matters, and it will not spell the end of document review or the position of
document reviewer.
For a further discussion of, and thoughts on, predictive
coding’s impact on document review and document reviewers, please read part two
of this series, which will be posted in the coming days.